Affiliate Disclosure: This post may include affiliate links. If you click and make a purchase, I may earn a small commission at no extra cost to you.
In a previous article, we discussed that data for a computer is nothing but a series of bits. Without any space and without any other numbers or characters except “0” and “1”. There could be billions and trillions of them. The bigger the number of these bits in a file, the more resources a system will require to compute, manipulate, save, retrieve, and transfer it. This is where data compression comes into play, reducing the storage space, bandwidth, and processing power required for the same amount of data.
Data Compression has two key roles: saving storage space and faster transmission. The working of data compression isn’t effortless to understand because very complex algorithms work behind both encoding and decoding of the data. However, we get results that actually help us save computer and transmission resources.

At its heart, data compression works by finding and eliminating redundancy. Imagine writing the sentence, “I like old songs and old movies.” The word “old” is redundant. You could create a rule: wherever you see the number ‘1’, replace it with “old”. The sentence becomes “I love 1 song and 1 movie.” We basically reduced the size of the sentence just by setting a rule. These rules are established using compression software and algorithms, and it is essential to remember them so that they can be decompressed when needed. In other words, at the retrieval end, we must know that “1” means the word “old”.
Do you see what we did here?
The sentence “I like old songs and old movies” has more characters than “I like 1 song and 1 movie”.
We essentially reduced the number of characters, and therefore the required number of bits to store or transmit this data. All compression algorithms are just more sophisticated versions of this basic idea.
How is data stored on a disk?
Computer data comes in many types. However, we will start at the very basics by understanding how the “text” data is stored on your hard drive or SSD. Let’s discuss the English text to make things even easier.
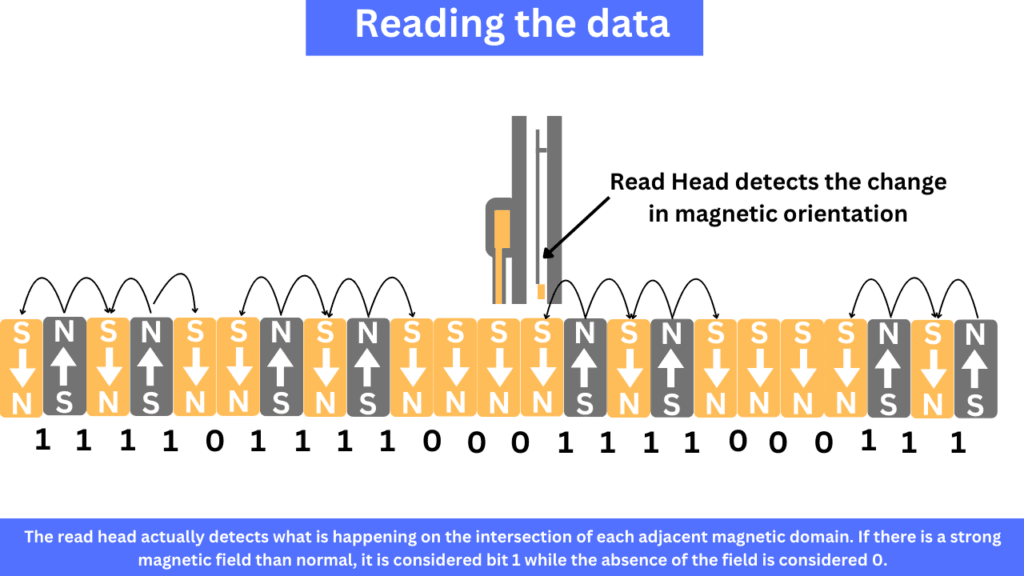
On a modern computer, each English character takes exactly 8 bits (1 Byte) of data. So, to store an English text, you would require 8 bits of data on a drive. On a hard drive, these bits are stored in the form of magnetic orientations.

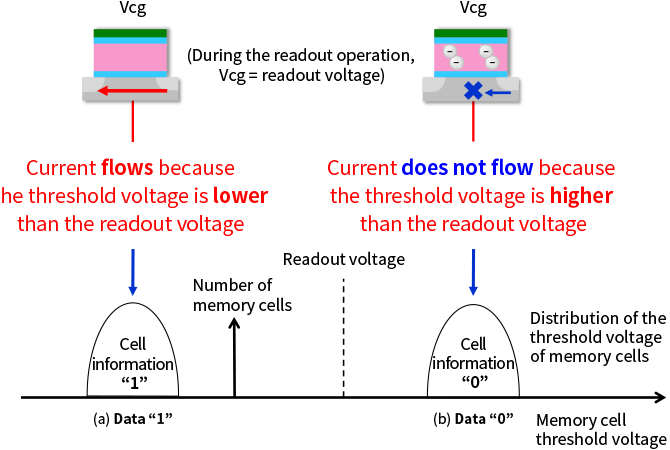
However, on an SSD, it is the electric charge in the memory cell that represents these bits.
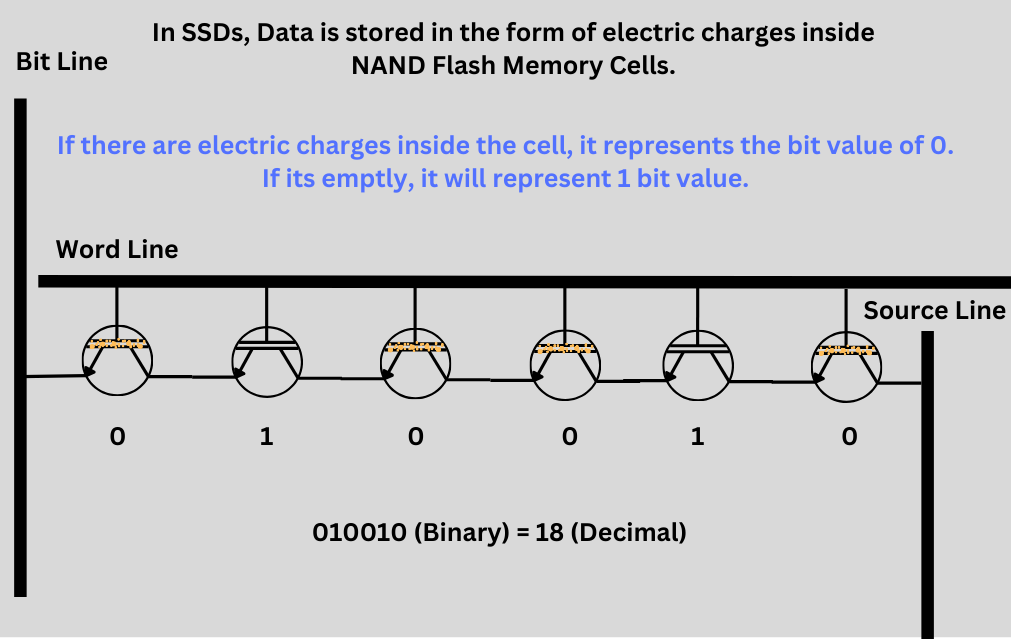

Now, we have 256 possible combinations of those 1s and 0s, and hence we can have 2^8 = 256 characters. This is enough for numbers, the English alphabet, and characters as well. Even for the spaces, computers use bits because, on the very low level, there are no spaces and just a massive string of 0s and 1s.
Now, any sentence or paragraph that we write will have some redundancy. Meaning, it will have repeating characters. Now, we can set a rule to assign specific bits to specific characters. Now, in the actual code, we do not have to repeat the whole 8 bits for each repeating character; we can use a special, shorter code that saves us the total storage space.
The role of data compression in storage and transmission efficiency
Compressed files take up less disk space. For example, a 2 GB text file may compress to 600 MB with lossless compression. Additionally, it saves storage space, resulting in lower costs for data centers and personal storage. The backups are faster because smaller files are quicker to back up, copy, and restore. It also saves us bandwidth when we transmit data through the network.
Streaming platforms like Hulu, Netflix, and YouTube compress video to deliver content efficiently without overloading networks. In personal usage, we generally compress files into zip or RAR files to reduce email attachment size. Software like WinRAR, WinZip, and 7-Zip make these things easier for us, and we don’t have to understand what is happening behind the curtains. But data compression is used widely, whether you know it or not. It reduces the size of files, making it easier for our devices and networks to conserve resources.
A little about Huffman Coding
Let’s take the sentence “I love old books“. We already know that each character is usually stored using 8 bits. That means every letter like “o”, “l”, or even the spaces, gets its own 8-bit binary code. So, for this sentence with 17 characters (including spaces), the computer would typically store 17 × 8 = 136 bits.
But notice that some characters repeat. For example, “o” appears three times, “l” appears twice, and the space character appears three times. Instead of storing the complete 8-bit code every time these characters appear, we can compress the data by assigning shorter binary codes to the characters that appear more frequently.
This is what techniques like Huffman Coding do. The computer analyzes how often each character appears and builds a table where more frequent characters get shorter binary codes, and less frequent ones get longer codes. So instead of using 8 bits for every character, we might use just 3 bits for “o”, 2 bits for spaces, and maybe 6 or 7 bits for less common letters. The result is that the entire sentence takes fewer than 136 bits to store, saving space.
Now, Huffman coding isn’t the only compression algorithm, but it is the basis of most modern algorithms. Shannon Coding is another foundational name. For different types of compressions, various algorithms are used. So, let’s jump into it.
Real-World Impact & Use Cases
You might have seen WhatsApp and Telegram compressing images even if you have the option to choose high quality. WhatsApp mostly uses the JPEG-based lossy compression, which involves luminance and chrominance quantization, followed by lossy encoding.
Steaming platforms like YouTube and Spotify also use compression to save their resources. Streaming platforms like Netflix and Amazon Prime Videos use compression much more aggressively. We also use compression actively when we compress our files before sending them over the internet. Even the MP3 and MP4 files created by our devices are already compressed.
Here is an illustration of how compression helps in video streaming.
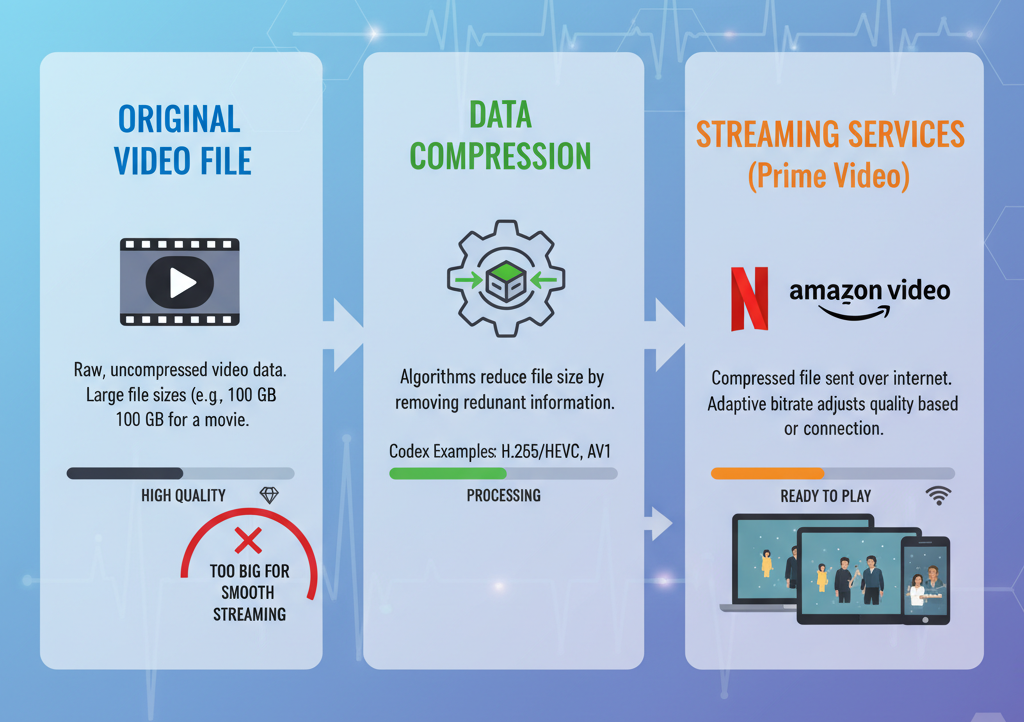
Types of Data Compression
Data Compression has many types and algorithms, but it can be broadly divided into two categories. Lossy and Lossless Compression. For example, we can use lossy compression for images and get away with a little less picture quality. However, we can’t do it like computer code, databases, and financial data. There, the lossless compression methods are used. Let’s understand them one by one.
Lossless Compression
As the name suggests, the lossless compression preserves the original quality of the data. No information is lost during the compression process, which makes it ideal for situations where data integrity is critical. Although the compression ratio is lower here, you still get some reduction in the size based on the type of your files.
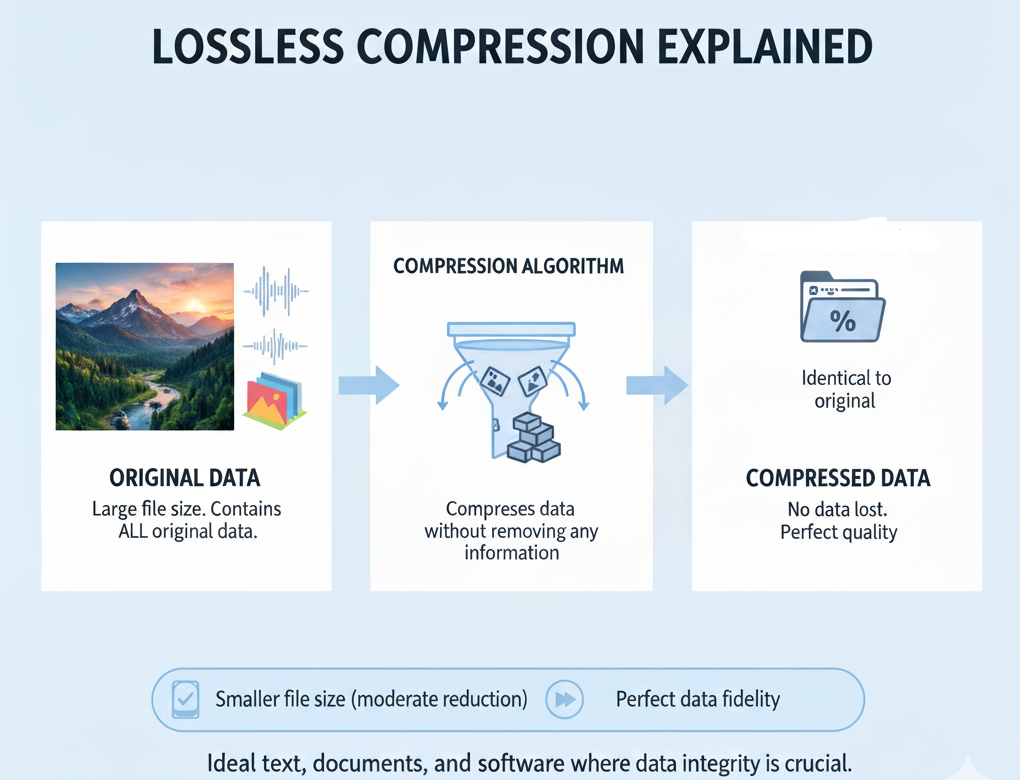
Let’s see the most common areas where lossless compression is used.
| Area | Examples |
|---|---|
| Text files | ZIP, GZIP, RAR (compressing documents, code, etc.) |
| Images | PNG, TIFF (graphics that need to retain original quality) |
| Audio | FLAC, ALAC (for audiophiles, music production) |
| Databases | Storing data efficiently without losing any details |
| Medical Imaging | MRI scans, X-rays (no data loss allowed) |
| Scientific Data | Satellite images, research datasets |
| Software Distribution | Ensures exact copies of files or programs |
The most common formats utilizing lossless compression are ZIP, PNG, GIF, and FLAC.
Lossless compression techniques reduce file size without losing any original data and are essential in formats where accuracy matters, such as text, images, and executable files.
Commonly used techniques include dictionary-based algorithms like LZ77, LZ78, and LZW, which replace repeated patterns with shorter references. These algorithms form the foundation of formats such as ZIP, GIF, and PNG. Entropy coding techniques like Huffman coding and Arithmetic coding compress data by assigning shorter codes to more frequent symbols, which are often used in conjunction with other methods.
Preprocessing techniques like the Burrows–Wheeler Transform (BWT) and Move-to-Front (MTF) reorder data to make it more compressible, commonly used in tools like bzip2. Simple methods like Run-Length Encoding (RLE) are also used in specific contexts where data has long runs of the same value, such as in TIFF or fax formats. Together, these techniques form the backbone of modern lossless compression systems.
Compression Ratios in Lossless Compression
The typical compression ratio in lossless compression is from 2:1 to 5:1. However, it depends on the redundancy in the file. For example, a 10 MB text file may shrink to ~4 MB with ZIP.
The point is that the compression ratio is lower, but it is good where data integrity is essential. It is widely used in applications such as databases, text, software, medical/scientific data, and any other area where accuracy is critical.
Lossy Compression
In lossy compression, the file size is reduced by removing some data. This lost data is usually imperceptible, non-recoverable, and unnecessary. This compression is used when some data loss is acceptable for achieving significant size savings. The most common examples of lossy compression are JPEG, MP3, MP4, and WEBP.
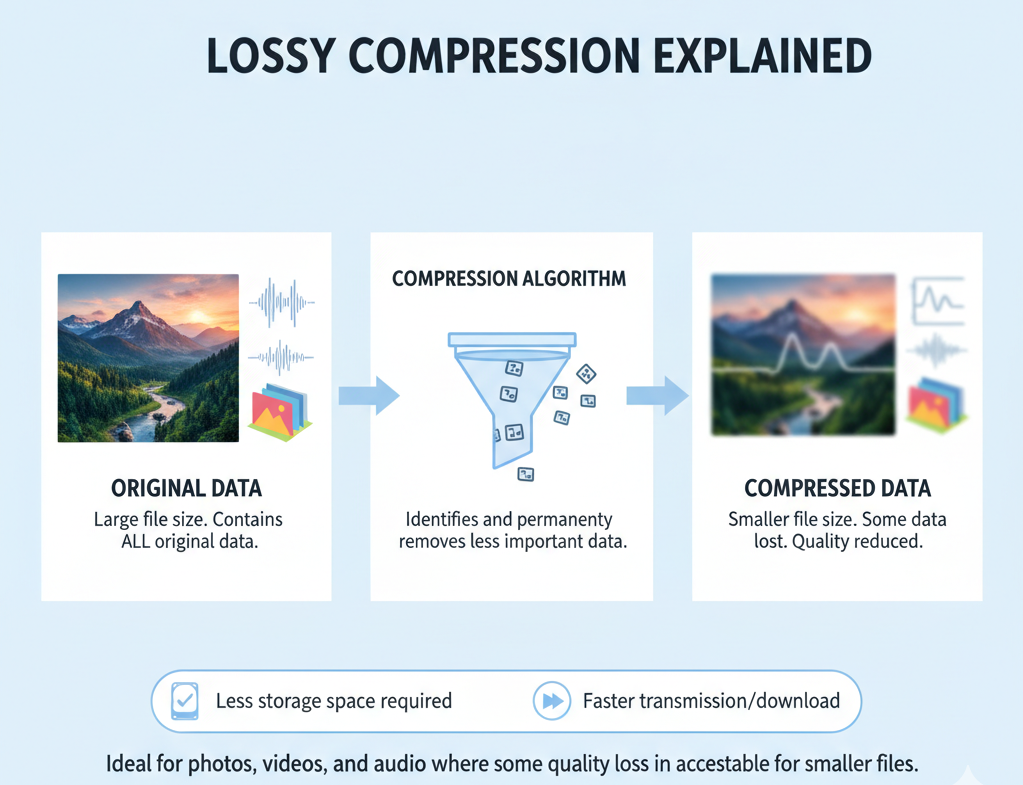
It is ideal for applications such as images, audio, and video, where perfect accuracy is not required, but efficiency and reduced storage are more important. Although the compression ratio is much higher than with lossless methods, it comes at the cost of not being able to restore the original file fully.
| Area | Examples |
|---|---|
| Text files | Rarely used |
| Images | JPEG, WebP, HEIC (photos, web graphics) |
| Audio | MP3, AAC, OGG, WMA |
| Video | MP4 (H.264/H.265), AV1, VP9 |
| Streaming Media | YouTube, Netflix, Spotify |
| Video Conferencing | Zoom, Teams, Google Meet |
| Web Optimization | Compressed images, video, and audio for faster website loading |
| Mobile Apps | Rarely used because lossy compression is unsuitable for code or documents |
Commonly used techniques in lossy compression include transform coding, such as the Discrete Cosine Transform (DCT), used in JPEG and MP3, which converts data into frequency components and removes those that are less perceptible to the human senses.
Quantization is another key step, where less essential details are approximated or discarded to achieve higher compression. Additionally, methods like perceptual coding exploit the limitations of human vision and hearing, thereby eliminating information that is unlikely to be noticed. Modern formats, such as AAC, HEVC (H.265), and WebP, often combine these approaches with entropy coding (e.g., Huffman or Arithmetic coding) to further reduce file size efficiently.
Preprocessing techniques in lossy compression often involve color space conversion, such as transforming images from RGB to YCbCr, which separates brightness from color information to enable more effective reduction. In audio, psychoacoustic modeling analyzes which sounds are less likely to be perceived and safely removed. Techniques like chroma subsampling reduce the resolution of color information while preserving detail in brightness, since the human eye is more sensitive to luminance. Combined with transform coding, quantization, and entropy coding, these preprocessing steps form the backbone of modern lossy compression systems.
Compression Ratios in Lossy Compression
We generally achieve a 10:1 to 100:1 compression ratio in lossy compression methods. For example, a 5 MB JPEG image can easily shrink to 500 KB with little visible difference. This saving can be much more in video files, where a 1 GB video can be compressed to 100 MB for streaming.
But, as we discussed earlier, some data is lost forever, and the quality can degrade if compressed too much. Lossy compression is widely used for streaming video (e.g., Netflix, YouTube), music (e.g., Spotify, MP3 players), web images, and video calls.
Conclusion
Whether lossy or lossless, we are using compression in some way in our daily lives. Some people do it actively by compressing their larger files and making them smaller. So use it by watching YouTube videos, streaming movies online, etc. The purpose is the same everywhere. We try to save our precious resources for storing and transmitting the data by compressing it.