Affiliate Disclosure: This post may include affiliate links. If you click and make a purchase, I may earn a small commission at no extra cost to you.
Sequential and Random Read/Write performance is critical for understanding the concept of digital storage. These concepts apply both to consumer and enterprise storage devices. You might have seen these names in your SSD or Hard Drive specifications. Sequential performance is consistently higher than random performance in all drives.
The main difference between random and sequential data is in their access patterns. Sequential data is accessed and stored in continuous blocks, resulting in less overhead on storage controllers. It is easy to store a large file in continuous blocks without worrying about keeping track of its locations. It can be accessed in the same manner. We just need to know the start and end locations of the data.
The random data doesn’t work in the same way. Because the data comes in different file types, sizes, and portions, they must be separated from each other. For reading the data, the data can be accessed from big chunks, but in different portions. So, random data represents how the data is accessed from the storage location. This puts many extra layers of data management. The controllers must work harder to keep track of the locations and prepare different storage areas.
Random data is much more complicated to store and access. However, it is the most important criterion determining the software performance, database management, OS functions, and almost everything that we do on our computers daily. Let’s talk in detail about both. But first, let’s examine this storage access pattern visualizer to gain a basic understanding of what we are talking about.
Storage Access Patterns Visualizer
What is Sequential Data?

Sequential data refers to data where the order of the data is essential. For example, a video file must be stored in the same place in a sequence. Changing the order of the sequence would make the stored data invalid. The sequential data generally includes the same types of files or large files of a specific kind. Also, even the random files stored sequentially in adjacent blocks can be considered sequential. For playing an audio, the data must be accessed in a series, and there is no need to either store it or access it from random locations. It is best to keep it as a single file, which acts as sequential data.
Sequential data is stored inside the storage devices in a linear order. It is stored and accessed in sequence, one after another, without jumping from one storage location to another. Because the sequential data has a linear access pattern, it enables a continuous flow of data that could be scaled through higher bandwidths. A good example of sequential data is when you watch a video; the data (frames) is sequentially read from the storage drive from start to finish for a smooth playback.
If data is stored sequentially, it will be read sequentially as well. This is because the flow or the sequence of the data location over time matters the most. It is more efficient to store video files in adjacent data locations rather than cutting them into parts and storing them at separate locations. This would make the data storage.
Streaming video and audio files, performing backups, moving images/videos, etc., are some of the tasks that involve sequential data. In other words, order is everything in sequential data. If there is no order in the incoming or outgoing data, it isn’t sequential at all.
A little about Sequential Read and Sequential Write?
Reading and writing sequential data enable the utilization of higher throughput. Additionally, since the need for repositioning between operations is reduced, latency is lower, and overall bandwidth is utilized more efficiently.
Even in hard drives, because the read/write head doesn’t have to rush, the sequential read/write speeds are good. The block sizes are bigger when a storage drive works with sequential data. Even defragmentation is the process of reclaiming and combining scattered data, keeping it all together so that mechanical movement is reduced. All in all, data is read or written in consecutive blocks without needing new commands for each block.
Now, in both hard drives and SSDs, there is a buffer that keeps the hot data to speed up the read operations. This is the data that is used primarily by any running applications. To artificially enhance write speed, caching is generally employed, such as the Pseudo SLC Cache used in SSDs.
What is Random Data?
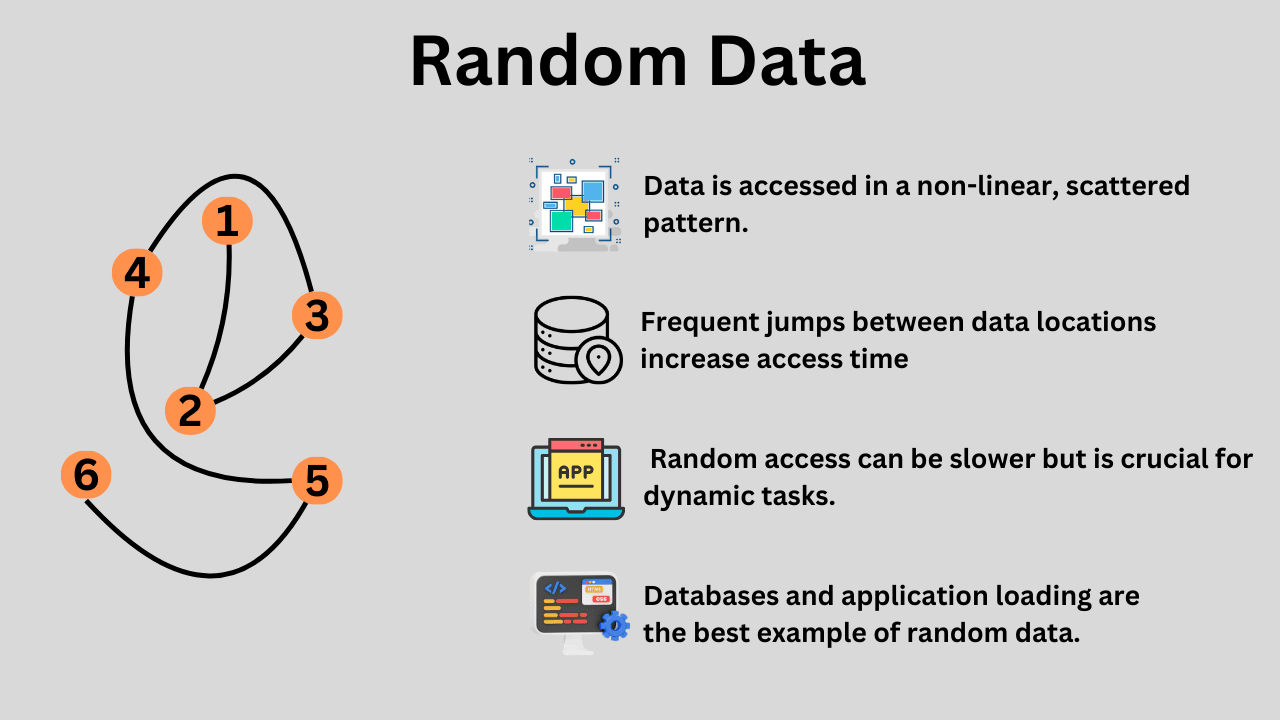
Random data is the complete opposite of sequential data because it lacks order. There are generally small and multiple files that are stored, accessed, or erased in the storage devices. It is accessed or written in a non-sequential, non-linear, and unpredictable manner. Don’t confuse the word random with the data itself lacking a structure. It has a structure but its access pattern is non-continuous.
The best example of random data is your OS/application/software/games. For example, if you are opening Google Chrome, it will never ask for a single file. There would be different files of different sizes and different formats for cache, history, bookmarks, cookies, images, webpages, themes, extensions, etc. These files would be stored at different locations because there is no point in storing them sequentially. After all, no one knows if they would be required at the same time or not.
The best word for random is fragmented data; however, it is not limited just to this. Random data is stored in non-contiguous blocks, which results in higher latency compared to sequential data. Generally, you will find your storage drives with very low random read/write performance compared to the sequential performance. This is because there is a huge overhead in both reading and writing random data. Even for reading random data, finding the data locations and ensuring proper data delivery is a time-consuming task.
Random data could be accessed from large sequential data sets, which sounds quite contradictory to what we just discussed. Yes, from a big file, we may have to access different portions for our use. This access pattern makes it a random read task.
A little about Random Read and Random Write?
Frequent location lookup is the most important part of reading the random data. For writing the random data, location allocation becomes the most important part. All these things are done by the controller and the operation system together, with regular updates to the mapping tables.
For reading the random data, small data blocks are accessed from their respective locations, and even if the drive has very high bandwidth, very little of it is utilized. For writing as well, the burst data inputs are absorbed by the write cache, but the actual writing on the flash or platters is done lately when the drive is free. Also, if the cache gets filled with the incoming data, the real drive write performance can be seen, which is very low in case of random data. So, there is lower throughput, which is generally measured in IOPS. Latency is high because of independent positioning and processing requirements.
The Ease of Storing Sequential Data
Because sequential data is stored in contiguous data blocks in every storage device, it is pretty easy on the system, storage medium, controllers, and almost everything else. There is no need to track and manage the scattered pieces of data. In hard drives, storing sequential data requires minimum write head movement over the spinning disk. Additionally, in SSDs, the controller can continuously prepare nearby blocks and write the data to adjacent pages. In other words, writing sequential data incurs no significant overhead, and storage devices can easily streamline this process without incurring extra power consumption or energy usage.
When it comes to reading the sequential data, the controllers can easily predict the next block, page, or sector (in hard drives) to be read. Fetching big chunks of data is possible, and the cache can be utilized in a much better manner. All in all, storing, retrieving, and erasing sequential data is much faster due to simple data management, continuity, reduced fragmentation, and big file sizes.
With the help of faster interfaces such as PCIe and NVMe, we can easily utilize parallelism in SSDs and achieve higher bandwidth to reach new limits in sequential data performance.
The Hardships of Storing Random Data
The biggest problem with storing random data is its fragmented nature. The data has to be stored in different locations to ensure it’s separated from other data. So, it will be stored in non-contiguous blocks. This leads to fragmentation, and as time passes, the data has to be modified and rewritten for reliability. This scatters the files, which degrades the performance. Managing fragmented data is much more resource-intensive for the storage drives.
The access time is slower because, in hard drives, the read head has to move in discrete locations in different parts of the platters. This significantly reduces retrieval and access time. In SSDs, reading random data is challenging because the FTL must be accessed repeatedly to locate the data. Additionally, switching between different blocks and pages takes time, which increases the overhead.
Unlike sequential data, the data locations of random data are unpredictable. Therefore, optimization is particularly challenging in this case. In hard drives, there is always the need for defragmentation to maintain performance. It adds an extra layer of data maintenance.
Unfortunately, it is challenging to effectively utilize the high data bandwidth and parallelism offered by PCIe and NVMe to improve random data access. Random data is primarily dependent on IOPS (Input/Output Operations Per Second) and latency, rather than throughput and bandwidth. However, with the new generation SSDs, the random read/write speeds are increasing, but they are significantly lower than the sequential performance.
Why are the access patterns different?
We understood that sequential data has a predictable and linear access pattern, while random data has an unpredictable access pattern. But why does that happen? It is very easy to answer.
The sequential data is ordered, which means each piece of data is logically connected to the next. Random data, on the other hand, is accessed based on specific needs.
The access patterns differ because the types of data are different. If the SSD can access the data easily because it is located in nearby locations, its performance would be better. On the other hand, if the SSD controller has to read the mapping table for multiple small files to locate them and then read from them, it would take a lot longer.
So, it is about the type of data that makes the difference in its access pattern. See, it is not that there is a difference in the data. Whether it is sequential or random data, computers understand only the language of logic and bits. Sequential data is a continuous stream of bits that can be easily directed toward a large area without much organization. The random data isn’t a stream but fragments of different files.
Sequential vs Random Read/Write performance in storage
The performance metrics for sequential and random read/write performance in storage vary depending on the type of storage device. However, the following are some average numbers to consider.
Hard Disk Drives (HDDs):
Sequential Read/Write Performance:
Read Speed: Typically around 100-200 MB/s.
Write Speed: Typically around 80-160 MB/s.
HDDs have rotating platters and moving read/write heads. The data is stored inside the sections which are divided into tracks on the platters in circular shapes. The read/write heads perform best when accessing data in a continuous stream, minimizing the time spent moving the head.
Random Read/Write Performance:
Read Speed: Typically around 0.5-2 MB/s.
Write Speed: Typically around 0.5-1 MB/s.
Random access involves frequent head movements because the head must move above the data locations, which are generally far apart. It significantly increases latency and decreases throughput compared to sequential operations.
Solid State Drives (SSDs)
Sequential Read/Write Performance:
Read Speed: Typically around 500-10000 MB/s (for SATA SSDs to Gen 5.0 NVMe SSDs).
Write Speed: Typically around 400-10000 MB/s (for SATA SSDs to Gen 5.0 NVMe SSDs).
SSDs have no moving parts and can read/write data across many cells simultaneously, making sequential access very fast. The power of parallelism combined with high PCIe bandwidth helps the NVMe SSDs reach very high sequential read/write speeds. Some Gen 5.0 NVMe drives are capable of offering above 10 GB/s sequential read/write speed.
Random Read/Write Performance:
Read Speed: Typically around 50,000-12,00,000 IOPS (Input/Output Operations Per Second) for random 4K reads.
Write Speed: Typically around 20,000-1,000,000 IOPS for random 4K writes.
SSDs handle random access much better than HDDs due to their lack of mechanical movement and their ability to access multiple cells at a time. The Gen 5.0 NVMe drives, again, can reach higher random read/write performance due to more effective use of parallelism and other optimizations.
Conclusion
Random and Sequential read/write performance is all about the access patterns of the desired data. If the access pattern is sequential, the data is coming from the storage in sequence. The same goes for storing the data. Random data is much more complex to read and write. So, random performance will always be slower compared to the sequential performance on the same drive.





Great Article Man!
thanx