Affiliate Disclosure: This post may include affiliate links. If you click and make a purchase, I may earn a small commission at no extra cost to you.
The CPU cache plays a critical role in reducing CPU bottlenecks. Because CPUs can be so fast, it is crucial to have memory with nearly zero latency and high bandwidth. The cache memory inside the CPU does that job. This memory is used as a high-speed memory that stores frequently accessed data and instructions. Therefore, instead of retrieving the required data from main memory (RAM), the CPU has its own faster memory, which helps improve CPU performance.
Without a cache, a CPU won’t be able to show its actual performance because it would always have to be waiting, looking for data either from RAM or secondary storage.
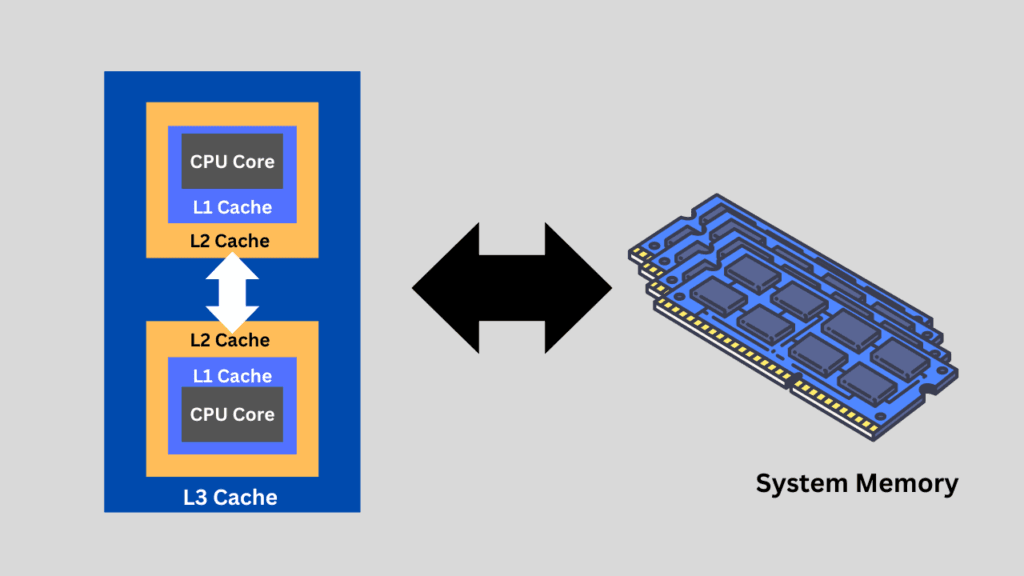
A CPU cache is a small, high-speed memory located inside or very close to the processor that stores frequently accessed data and instructions. Its primary purpose is to reduce the time it takes for the CPU to access data from the much slower main memory (RAM). Modern CPUs have multiple levels of cache (L1, L2, and L3), with L1 being the fastest but smallest, and L3 being larger but slightly slower.
The cache works by predicting and storing data that the CPU is likely to need soon, which significantly improves performance by minimizing delays. Without a cache, the CPU would spend much more time waiting for data from RAM, slowing down overall system speed. This can be worsened in tasks that require repeated access to the same data, like running loops, functions, or frequently used programs. Let’s understand in more detail.
Let’s understand the broad CPU working basics first.
The three main components of the CPU are the Arithmetic Logic Unit (ALU), the Control Unit (CU), and the Registers. The ALU is the main element responsible for most of the critical processing that makes the CPU what it is. However, the Control Unit directs the processor’s operations. It means the control unit instructs the ALU and memory on what to do based on the instructions. Registers are high-speed memory within the CPU that hold the data and instructions in real time when the CPU is processing them.
The Fetch-Decode-Execute cycle, even for minimal operations, will have some outputs that must be stored in memory. These results are stored temporarily in the registers. If these results are required again during ongoing operations, they will stay in the registers. The registers store operands for arithmetic operations, intermediate results, and control information. However, if the results are not required immediately or are very large, they will be stored in main memory. The CPU will have the memory addresses to read from and write the RAM.
The cache serves as an intermediate memory location between the CPU (Registers) and main memory (RAM). Now, instead of moving the results to the RAM, the CPU can keep them in the cache if they are being used frequently. Cache memory is faster than RAM, so using it for the often-accessed data leads to a very low latency.
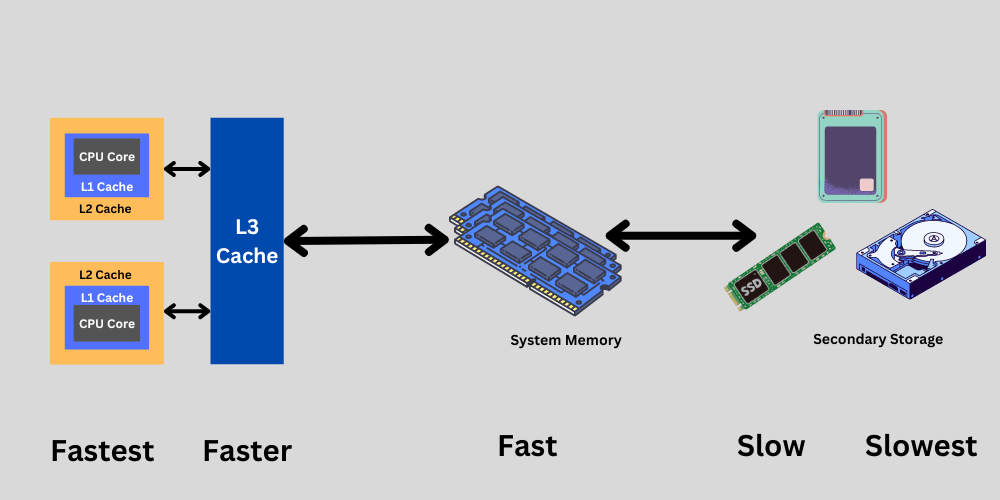
The operating system primarily handles memory management. It keeps track of where the data is stored and makes sure there are no conflicts. The registers and Cache have limited memory space, often in Megabytes (Cache) and Kilobytes (Registers). However, we can run large programs that may require gigabytes of memory (RAM). Therefore, cache memory is often used to store the most frequently accessed data. How is this decision made? The CPUs have their algorithms, such as LRU (Least Recently Used), to determine which data to keep in the cache based on usage patterns. Additionally, software developers can optimize their applications to utilize data access patterns effectively.
How is the CPU Cache made?
The CPU cache is composed of SRAM (Static Random Access Memory). It is a volatile memory, just like DRAM, but it exhibits static behavior. It means the stored data will remain there without the need for refreshing as long as the input power is present. Static RAM is composed of transistors (six transistors comprise a single SRAM cell, which stores one bit of data), and the basic storage unit is called a Flip-Flop. Static RAM is challenging to scale and expensive to implement. This is why it has its applications in critical areas, such as caches, networking devices, and digital cameras, among others.
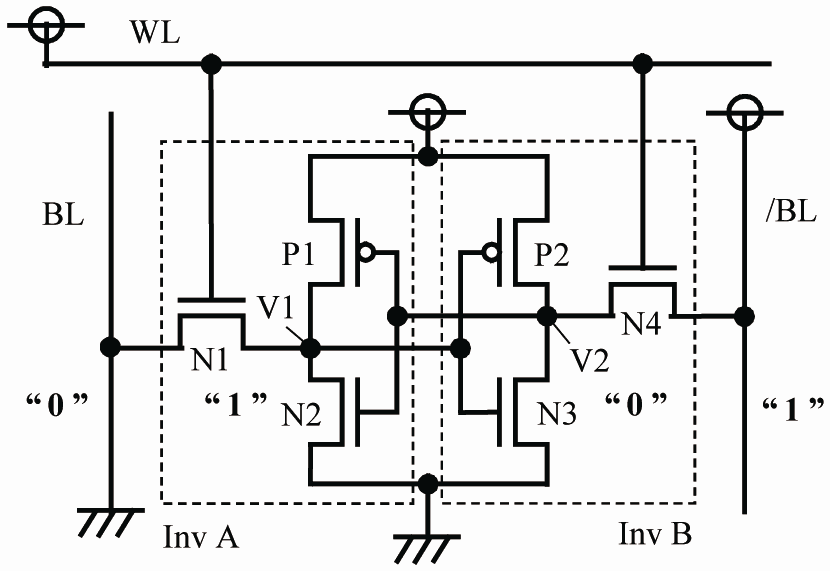
Because Flip-Flops uses the transistors as the storage medium, it becomes capable of achieving very high data read/write performance. This is because the transistors can switch pretty fast (more than 800 Gigahertz). With the help of transistors, flip-flops, and hence the cache, they become capable of impressive performance compared to any other storage medium. However, because storing just a bit of data requires six transistors, scaling SRAM is a challenging task. This is the reason the Cache has a limited size in CPUs and cannot be used in other places, such as DRAM, as primary memory.
Types of CPU Cache

1. L1 (Level 1) Cache
L1 cache is the fastest, closest, and smallest cache embedded within each CPU core. The most common size for L1 cache is 64KB, but it could vary between 16KB and 128KB. Older CPUs may also have less than 16 KB. The L1 Cache can be utilized for two primary purposes: as an L1 Data Cache or an L2 Instruction Cache. The primary role of the L1 cache is to store the most frequently accessed data and instructions by the CPU core. The cache reduces the latency by not fetching the data from the L2, L3 Cache, or the main memory.

Size and Speed
The L1 Cache generally comes in sizes ranging from 32 KB to 64 KB. Most modern and faster CPUs will have an L1 Cache size of 64 KB. The theoretical speed can vary between 50 GB/s and 100 GB/s. Because the L1 cache generally works at almost the same speed as the CPU, the effective speed becomes pretty high compared to other memory mediums. In case of cache hits, the data can be provided to the CPU within 1 to 3 cycles.
How does L1 cache work?
If the CPU demands any data or an instruction, the first step is to check the L1 Cache for that data. If the data is available in the L1 Cache, it is called a cache hit. With a cache hit, the CPU retrieves the required data in just a few clock cycles (typically 1-3 clock cycles). A cache miss occurs when the required data isn’t available in the L1 cache and the CPU must access the L2, L3, or main memory (RAM).
The CPU decides which data to place in the L1 cache using the methods called temporal locality and spatial locality. With temporal locality, the CPU identifies recently used data and predicts that it may be used again in the future; hence, it uses the L1 cache to store that data. The spatial locality is much more predictive in nature. In this, the data near the recently accessed data is moved to the L1 cache (mainly from the same block in the memory).
However, due to the smaller size of the L1 cache, the selection of data is crucial. For replacing data, the CPU uses algorithms like LRU, in which the least recently used data is replaced with new data. However, some CPUs also use random replacement methods, which can simplify things because algorithms tend to increase the workload and slow down the process.
CPU cache is generally designed to be associative in nature. The cache is divided into multiple sets, each with a specific number of lines to store data. To understand it better, associativity answers this question: “Where in the cache should a specific piece of data from memory go?” More specifically, associativity defines how memory locations are mapped to these cache lines.
The process of Cache Memory Mapping
The main memory (RAM) of your computer retrieves data from secondary storage in the form of processes. Each process is subdivided into pages. The main memory, on the other hand, is divided into equal-sized frames. The size of each frame is the same as that of each page. The process of this subdivision and bringing the processes to the main memory is the job of the operating system.
However, to move the elements from the main memory to the cache memory, the main memory is divided into blocks, and the cache is divided into lines. The line size is the same as the block size. The process of mapping data from memory blocks to cache lines is called mapping. This was an abstract way of saying that numerous steps are involved in converting the address and data values when mapping them to each other.
There are three main types of cache memory mapping methods used in CPU cache. These are as follows.
| Cache Type | Flexibility | Performance | Complexity |
|---|---|---|---|
| Direct-Mapped | Low (1 specific line per block) | Fast lookup, but high collision rate | Simple hardware |
| Fully Associative | High (any line for any block) | Best performance (no collisions), but slower due to search | Complex hardware |
| Set-Associative | Medium (n lines per set) | Balanced performance, fewer collisions than direct-mapped | Moderate complexity |
Functions and Roles of the L1 cache
The primary function, as we discussed earlier, is to store the data and instructions that the CPU uses most frequently. The L1 cache works at the same clock frequency as the CPU. The Instruction cache (L1) helps the CPU fetch instructions separately from data. The data cache stores the data while the CPU is actively working on any task.
The best thing about the L1 cache is that each CPU core has its own L1 Cache. It helps the cores with parallel processing and also minimizes delays caused by the shared cache. When the CPU needs to multitask, it may require a faster memory that can switch between different data sets. In this way, L1 cache offers major benefits in multitasking as well.
2. L2 (Level 2) Cache
The L2 Cache can be core-specific or shared. It means the L2 cache can be assigned just to the CPU or sometimes shared by multiple cores. Some CPUs with core-specific L2 cache include the Intel Core i7-9700 K, Ryzen 7 5800X, and Intel Xeon Gold 6248. Some popular CPUs with shared L2 cache include the AMD Opteron 6174 and the Q6600. Most consumer-oriented CPUs will have a core-specific L2 cache. The shared L2 cache is generally used in server CPUs.
The L2 Cache comes after the L1 cache and before the L3 cache. We talked about the cache miss above in the L1 cache. If the CPU demands some data and it is not present in the L1 cache, it will then check the L2 cache. Again, if it is a cache hit (meaning the required data is in L2 cache), the CPU will save some time searching it further in the following memory levels. L2 cache also helps in multithreading by providing faster data access to shared data among threads.
Size and Speed of L2 Cache
The smallest size of the L2 cache is 256KB, which is more common in low-end and older processors. The most common size is 512KB to 2MB. However, some high-end CPUs, and mostly the server processors, can have up to 16 MB of L2 cache.
L2 cache generally accesses the data within 3 to 10 clock cycles. The speed is lower than the L1 cache, but pretty fast compared to the main memory and the L3 Cache. The total speed of the L2 cache is generally within 50 to 100 GB/s. However, it varies heavily depending on the CPU architecture and clock speed. We can estimate the speed using this formula:
Data Transfer Rate (GB/s)=Clock Speed (GHz)×Bus Width (bytes)×2
Let’s take an example of the AMD Ryzen 7 5800X. It has a base clock of 3.8 GHz and can be overclocked up to 4.7 GHz. The estimated speed of its L2 Cache will be around 58 GB/s. The same formula goes for the L1 cache as well. However, the effective speed in the L2 cache will be slower due to the higher latency. Because the L2 cache requires 3 to 10 clock cycles to provide the data, the same speed will yield different results in the real world. However, this speed is breakneck compared to the RAM in our computers.
How does L2 Cache work?
The operation of the L2 cache is almost identical to that of the L1 Cache. The real difference is that it is a little farther from the CPU core, where the actual work is taking place. But, even though it is placed after the L1 cache, its capacity is higher. More frequently used data can be stored inside it. Again, just like the L1 cache, algorithms such as the LRU (Least Recently Used) are used to determine which data should be placed in the L2 cache.
L2 cache can also be direct-mapped, set-associative, or fully-associative. The real difference is in the latency at which the CPU accesses the data from the L2 cache.
Functions and Roles
If the CPU modifies it will first modify the L1 cache. But these changes can also be seen in the L2 cache. You can call the L2 cache a buffer for the L1 cache. It serves as an additional storage if the data is not found in the L1 cache. In multi-core CPUs, the coordination between the L1 and L2 cache is important. If the changes in the L1 cache aren’t reflected in the L2 cache, the L2 cache has stale data, which may not be helpful for the CPU.
3. L3 (Level 3) Cache
The L3 Cache sits just between the L2 cache and the main memory of your computer. It is a shared cache among multiple cores and their L1 and L2 caches. L3 cache has the largest capacity of all the cache levels, but also has the highest latency. You can call it a backup plan for the L1 and then the L2 cache. If the required data isn’t available in both L1 and L2 Cache, the L3 Cache will be searched for it.
If the CPU modifies data, the changes will also appear in the L3 cache. L3 cache uses coherence protocols so that any data on the cache is available to all the cores consistently. Also, it can track which core is changing or accessing the data. Again, multiple algorithms might be working to keep the most valuable data inside the L3 cache.
L3 Cache is generally set-associative, which means it can use multiple ways to store any given cache line.
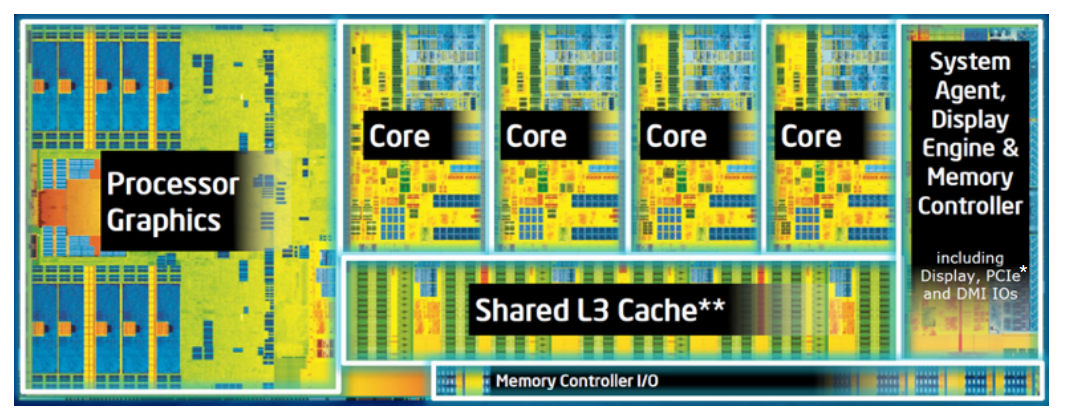
Size and Speed of L3 Cache
L3 Cache generally has a size between 2 MB and 64 MB. Most consumer CPUs will have an L3 cache between 3 MB and 20 MB. Server CPUs can even have an L3 Cache bigger than 64 MB. The access time is generally within 10 to 20 nanoseconds. The latency is higher than the L1 and L2, i.e., between 10 and 20 clock cycles.
How does L3 Cache work?
The L3 cache works almost like the L2 cache. The real difference is that it sits even farther from the CPU core and is typically shared among multiple cores, rather than dedicated to just one. Like the L1 and L2 caches, cache replacement algorithms such as Least Recently Used (LRU) are used to manage which data stays in the L3 cache. It can also be set-associative, fully-associative, or direct-mapped, depending on the design. The main trade-off is in latency. The L3 cache is slower than L2, but still significantly faster than accessing data from main memory (RAM).
Functions and Roles
If the data is not found in both the L1 and L2 caches, the CPU then looks into the L3 cache. In multi-core processors, the L3 cache plays a crucial role in coordinating data access across cores. If one core modifies data, that change can be visible to other cores through the L3 cache. This helps maintain consistency and prevents different cores from working with outdated (stale) data.
4. L4 (Level 4) Cache
Some rare CPUs, such as Intel’s Haswell or IBM’s Power9, can also have an L4 Cache. Most of the time, the L4 cache is made up of eDRAM rather than SRAM. The L4 Cache has a significantly larger capacity than the L3 cache, typically ranging from 128 MB to more. L4 Cache is slower, with the latency ranging between 20 and 30 nanoseconds. L4 Cache has an interesting name: victim cache. The data that is evicted from the L3 cache is stored in the L4 cache. However, because it is relatively rare in both consumer and server CPUs, we won’t discuss it in detail.
Frequently Asked Questions about CPU Cache
Does more CPU cache always mean better performance?
Not necessarily. While having more cache generally reduces the need to fetch data from slower main memory or storage, there are diminishing returns. Beyond a certain point, increasing cache size adds latency, cost, and power consumption without dramatically improving performance. The efficiency of cache design and how software uses memory often matter more than raw size.
What is cache coherence?
In multi-core processors, each core has its own cache. Cache coherence ensures all cores see the same value for a piece of data. Without it, one core could be working on outdated information while another has the latest update. Modern CPUs utilize protocols such as MESI (Modified, Exclusive, Shared, Invalid) to maintain cache synchronization.
How does software affect CPU cache performance?
The way a program accesses memory has a big impact on cache efficiency. Programs that access data sequentially (like iterating through an array) benefit from spatial locality, meaning more cache hits. On the other hand, random memory access patterns can cause frequent cache misses. Writing cache-friendly code often results in significant performance gains.
What is a cache hit?
A cache hit happens when the CPU finds the data it needs already stored in the cache. This is ideal because cache is much faster than main memory, so the CPU can continue without delay. The higher the cache hit rate, the better the system’s overall performance. On the other hand, a cache miss forces the CPU to fetch data from slower memory, which adds latency.
What is a cache line, and why does it matter?
A cache doesn’t store data byte by byte. It stores chunks of memory called cache lines, typically 64 bytes. When the CPU requests a single byte, the entire line is loaded into cache. This design makes sequential access faster, but it can waste space if the program only needs a small portion of that line. Understanding cache lines helps developers optimize memory access.
Can you upgrade or change the CPU cache?
No, CPU cache is embedded directly into the processor and can’t be upgraded or expanded like RAM. You can’t even see it with your naked eyes. However, you can influence cache performance indirectly. This can be achieved by selecting CPUs with larger caches, enabling BIOS features such as prefetching, or writing software that optimizes efficient use of the cache.
Useful Resources:
https://www.amd.com/content/dam/amd/en/documents/epyc-technical-docs/white-papers/58725.pdf
https://cseweb.ucsd.edu/classes/fa10/cse240a/pdf/08/CSE240A-MBT-L15-Cache.ppt.pdf





This is pure gold! So grateful you posted this 🌟
Glad you liked it.
Really Good Materials for reviewing CPU memory knowledge. Thanks!